Troubleshooting Dante/AES67/etc. For Dummies
Setting up an Audio Over IP network for the first time and having problems?
Background
Over the summer, we built our first AOIP-enabled radio studio. Based around an AEQ Forum Lite IP, a powerful digital mixer with 16×16 channels of Dante/AES67, we finally completed the project that had been delayed since the pandemic. Going in blind, we found the set-up and troubleshooting guides stopped short of solving our teething issues. It took us a while to find the optimum settings for the new studio. We learnt these lessons so you hopefully don’t have to.
This article assumes you’re briefed on what AOIP is, and know vaguely how it works.
Planning Your Network
You’d be forgiven for thinking that AOIP would work on a conventional gigabit network. However, not all network cards are equal, and neither are network switches.
For most setups, there is no need to run Dante through a switch (and if you do, it needs to be a managed switch as described here – most datacenter-class switches meet that spec – there’s no need to buy an uber-expensive ‘AV’ switch). Instead, just connect the two devices together directly with a decent CAT6 cable. The Dante Controller software lets you set the IP address of the card, so there’s no need to configure a DHCP server.
Most set-up guides will warn you that you shouldn’t mix conventional network traffic with AOIP, and that some ethernet adapters are not compatible. They may, however, stop short of recommending what network adapter to use on your PC for a virtual soundcard.
We first tried a gigabit Intel Pro 1000 PT adapter (a PCI-E card with two gigabit ports), but we weren’t able to get it to perform properly for AOIP.
In the end, we used the motherboard’s built-in Intel I219-LM adapter for AOIP, and a 4-port HP NC364T for general network-y stuff. We found the HP PCI-e card worked reasonably ok for Dante, but the connection was more jittery (with latency jumping from 1ms to 5ms quite often) which didn’t sit right.
Intel I210-based network cards (such as the Intel I210-T1, which is – at the time of writing – is under £40 on eBay) seem ideal for Dante. It’s worth checking what the model your built-in ethernet adapter uses – if it starts with i21, you can use that for AOIP – and a cheaper PCI-E card for general network access.
Clocks + Sync
In a Dante network, one device will become the clock ‘leader’. This means that all other devices in the network will sync to it, which stops separate channels of audio drifting out of sync (remember, in AOIP land, there are no stereo pairs unlike AES/EBU). If you open the Dante Controller software, you can explore clock status and see which device is the current leader.
The main symptom of a clock problem is intermittent audio. If you’ve set up your AOIP network, and audio either works just in one direction, or cuts out for a few seconds every so often, it’s probably the clock. In our case, audio was flowing into the desk from Myriad Playout, but we couldn’t record/stream what the desk was returning.
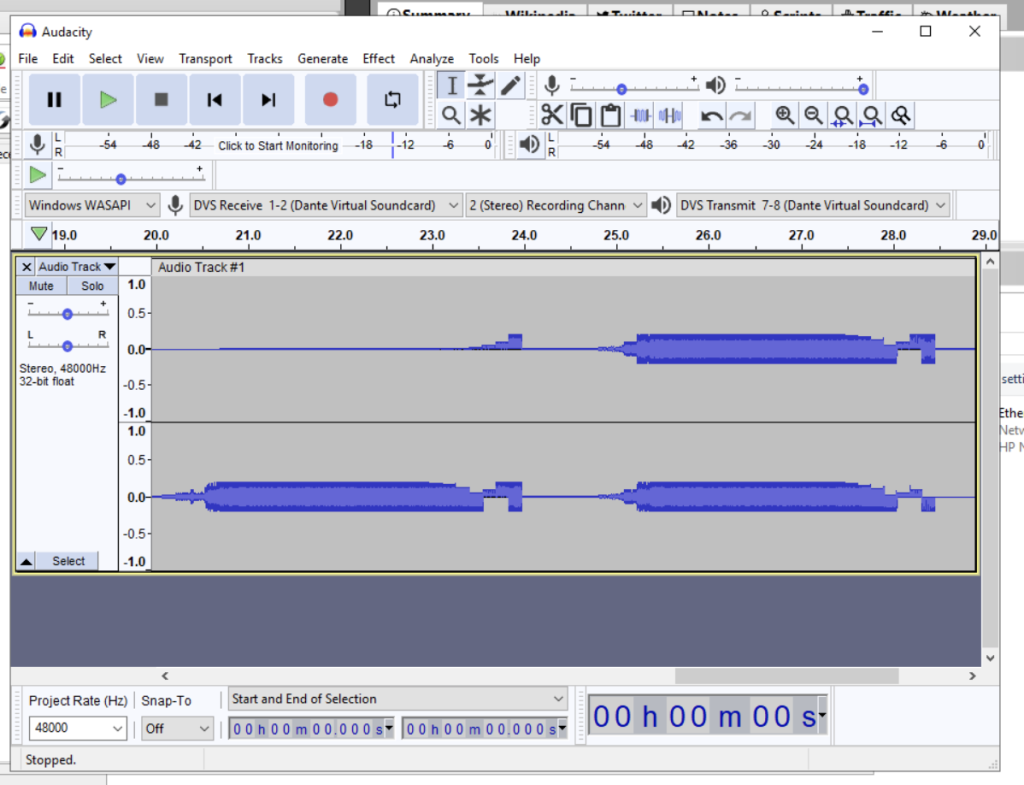
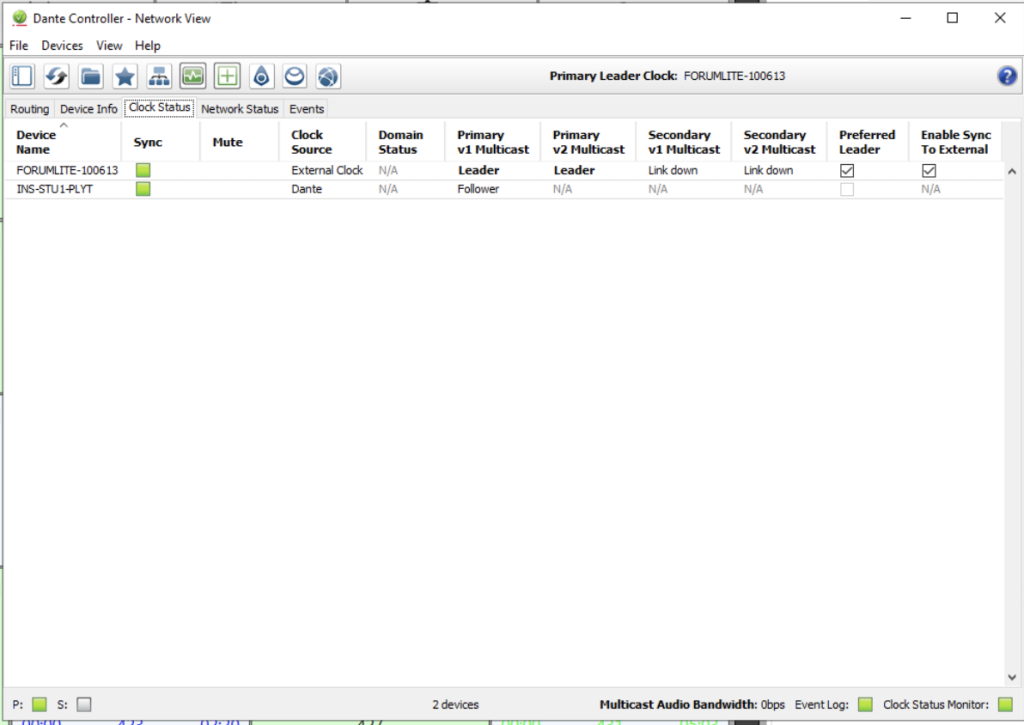
If your clock leader is the mixer core (in small setups, it probably is), then it is very likely that the Dante card needs to use the mixer’s internal clock, rather than the built-in one from the Dante card. This is because the digital signal processing core in most modern mixers will have its own clock.
In Dante Controller, make sure the “Enable Sync to External” option is ticked (rebooting the device as necessary). If this option isn’t ticked, the Dante card will run with a different clock to the mixer, causing weird symptoms, such as that of the first screenshot.
(A big shout-out to my colleagues Mark and Lee at Broadcast Radio for helping me troubleshoot this)
Reducing Latency
Everything was set up and on air, but we had a problem: sometimes (every 20 minutes to 2 hours), latency would spike above 10ms, which results in a brief but noticeable interruption to audio. Not good.
The official troubleshooting guide says to ensure that all power-saving modes are turned off on the network card. Looking in the Device Manager in Windows, indeed, they were.
Or, so we thought.
Without several confusingly-described utilities installed from Intel, it turns out the Energy Efficient Ethernet settings can’t be changed in Windows. After installing the Intel PROSet Adapter Configuration software, we had access to a couple of new settings.
In the end, we found the following settings to be optimum (changes from the default settings are bold; settings you might not see – without all the PROSet utilities – are in italics):
| Adaptive Inter-Frame Spacing | Enabled |
| Energy Efficient Ethernet | Disabled |
| Flow Control | RX & TX Enabled |
| Gigabit Leader/Follower Mode | Auto-Detect |
| Interrupt Moderation | Disabled |
| Interrupt Moderation Rate | Off |
| Log Link State Event | Disabled |
| Protocol ARP Offload | Disabled |
| Protocol NS Offload | Disabled |
| Receive Buffers | 256 |
| Reduce link speed during system idle | Disabled |
| Speed & Duplex | 1.0 Gbps Full Duplex |
| Transmit Buffers | 2048 |
| Wake On Lan (any related setting) | Disabled |
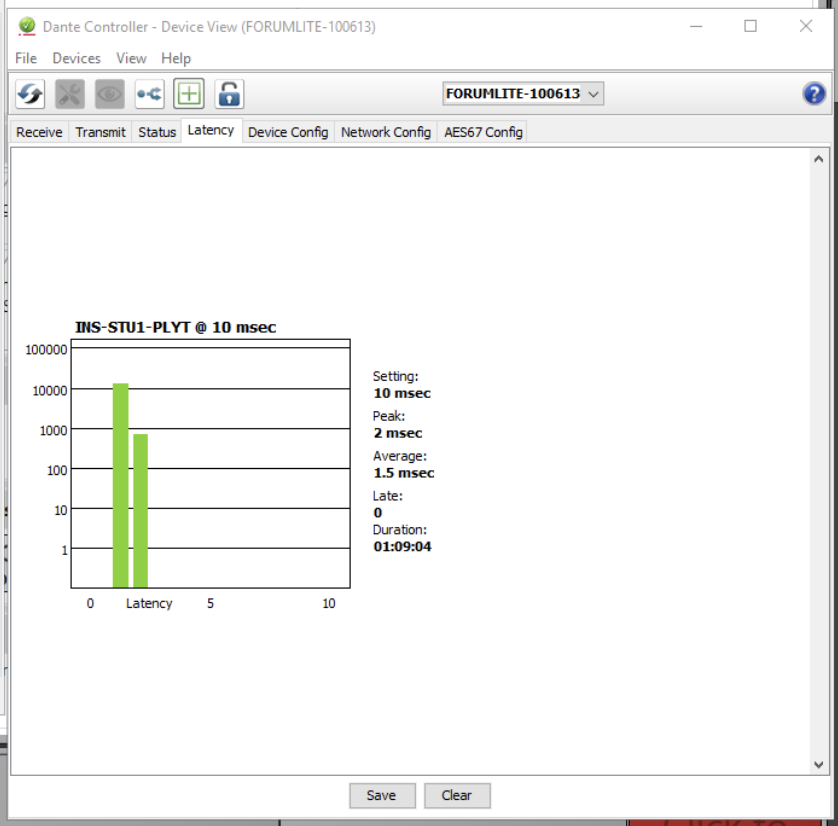
A week later and still no late packets.