Machine Learning for Automation
This isn’t at all what you might think it means.
Automation in broadcast is tricky. Computers aren’t always the best at deciding what two songs sound right when played back-to-back, and can leave you with some horrible segues. However, this can now be improved using cool modern tech.
tl;dr / Overview
This project required a few tweaks to the music scheduling software, and a Nerve module to automatically fill in information. Nerve is the custom-built music library that we built to ensure our library was audited and radio-frendly. In AutoTrack, one can use “Characteristics” to determine what songs can follow each other without sounding rubbish. This information and tech came from Spotify, in their acquisition of the Echo Nest. They trained a deep learning model with lots of music, which learnt how to categorise it. This ensures that songs with similar tempo, energy, and mood follow each other properly.
Loading the Information
Spotify provide a free web API. Nerve has, for a while, tried to tie every track on the system with a Spotify ID. In automation, the hit rate is around 95%. The other ten percent is made up of tracks with slightly different spellings between the Spotify platform and others, and artists who opted out.
Nerve makes requests to the Spotify search, like below:
https://api.spotify.com/v1/search?q=track:%22Flash%22+artist:%22Queen%22&type=track
It picks either the first result to perfectly match the title and artist, or the top result. The search tags used in the query work with many use cases, and there is not a single track in that 95% that is completely the wrong song. A few remixes are incorrectly tagged, but these are updated when we notice them.
Nerve then makes a request to https://api.spotify.com/v1/audio-features/XXX to load this information, which is stored in the library.
This information is then written to playout, in this case through the AutoTrack database.
Bonus: Mass Loading Information
When Nerve was created, it did not use Spotify. This was, in reality, an unfortunate decision, as MusixMatch quite frankly sucks (it’s an open platform that seems to be ridden with spam). Hence, we had to bootstrap the existing library to load in this information.
Spotify rate limit requests, but that didn’t stop us writing a simple script that just iterated through every track in the library, tying it to a Spotify ID where possible.
The next bit (loading audio information) used the https://api.spotify.com/v1/audio-features?ids={} API reference. It loaded 100 rows of track information at a time, significantly faster than before. Not all tracks on Spotify have an audio analysis, interestingly, so after about 24 hours (the 404 search results seemed to enqueue the tracks for analysis) we ran the script again. This time, near enough every track completed, as the Spotify backend seemingly noted it was missing.
All code is in the Nerve repository on GitHub, so you can use it free of charge for your own station. Migrating your library fully to Nerve is a bit of a pain. We’re investigating ways to make it easier, but sadly it’s not a priority at the moment. Feel free to hack on the code and make pull requests – we’ll accept ’em.
AutoTrack Scheduling
Four characteristics were defined: Energy, Tempo, Dancability and Mood. 1 through 6 were defined as Very Low to Very High.
Within AutoTrack, the global rules were edited. These became:
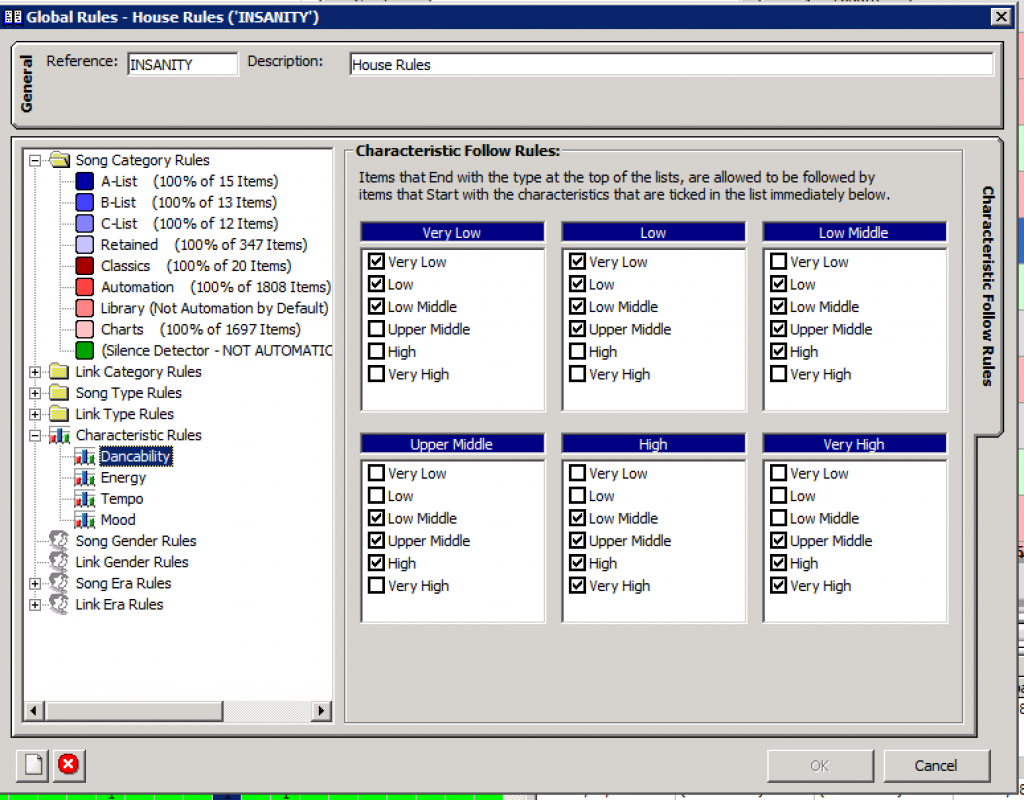
These stayed roughly the same for each characteristic. Energy changed a little from the above.
Next, the Clock Rules were updated. The Characteristic Follow rule became a guide, so it can be broken if necessary. It’s rare that this is needed, but initially about 10% of songs weren’t being scheduled/left blank, and we don’t want that.
Once the scheduler ran, we noticed that automation was much better to listen to. We saw a large increase in listener figures, with listeners staying tuned into the station for longer.